2025 年 1 月,Google 宣布将在移动端搜索结果中移除面包屑,但桌面端不会受到影响。
Google 在 Search Central 的更新中表示:
“移动搜索用户很快将看到搜索结果中 URL 的展示方式更加简洁、直观。面包屑最初作为‘网站层级结构’功能的一部分推出,但我们发现,对于使用移动设备进行搜索的用户来说,面包屑的实用性并不高,因为在较小的屏幕上往往会被截断。从今天开始,我们将逐步在所有支持 Google 搜索的语言和地区中,停止在移动端搜索结果中显示面包屑(桌面端搜索结果仍将继续显示)。”
面包屑结构化数据仍然是一个尚未被充分利用的 SEO 工具,可用于强化内部链接并巩固网站层级结构。正确实施面包屑可以提供一致的导航路径,帮助搜索引擎更好地理解内容的组织方式,从而在一定程度上支持大型、复杂网站的抓取与发现。
通过降低网站结构深度,并在页面之间建立系统化的内部链接,面包屑能够提高深层页面被发现和优先抓取的可能性。对于拥有庞大商品目录或内容库的企业级网站和电商网站而言,这意味着更多关键页面可以被索引,同时避免浪费宝贵的抓取预算。
在本指南中,我们将介绍面包屑的工作原理、正确的实施方法、需要避免的常见误区,以及如何进行监控和维护,以实现长期的 SEO 收益。
什么是 SEO 面包屑?
SEO 面包屑是一种导航链接,用于向用户展示他们在网站层级结构中的当前位置,通常以可点击的路径形式显示,例如:“首页 > 博客 > SEO”。
例如,在一个电子产品商城中,某个产品页面可能会显示:首页 > 电子产品 > 笔记本电脑 > 游戏笔记本 > ASUS ROG Strix,这有助于用户清楚地了解自己所处的位置,并实现更便捷的导航。

为什么面包屑对 SEO 很重要
面包屑之所以对 SEO 非常重要,是因为它们能够建立一致的内部链接结构,从而强化网站的层级体系。每一个面包屑本质上都是一个具有上下文意义的内部链接,将当前页面与网站架构中的其他层级连接起来。
当结合 BreadcrumbList 结构化数据 实现时,面包屑可以向搜索引擎清晰传达页面在内容层级中的位置,并提供结构性信号,帮助搜索引擎更好地理解内容是如何组织和相互关联的。
真实数据也充分说明了面包屑对搜索表现的重要性。Dave Ashworth 曾记录过一个案例:某网站在进行模板更改时,意外丢失了面包屑结构化数据。结果如何?自然搜索点击率(CTR)从 6.6% 下降到 4.1%,跌幅接近 40%。
但好消息是:在恢复面包屑后的三周内,CTR 反弹至 7%,甚至超过了最初的基准水平。这表明,面包屑不仅影响网站在搜索结果中的展示方式,还会直接影响用户是否选择点击你的页面。
算法所渴望的语义关系信号
BreadcrumbList 结构化数据有助于明确网站内容在层级结构中的组织方式,为搜索引擎提供一致的结构化上下文。Google 并不会只依赖关键词,而是会评估页面在整个网站架构中彼此之间的关系。
从 Google 的基于实体的索引机制来看,算法并不是孤立地评估单个页面,而是分析内容在网站整体语境中的关联性。当 Google 反复看到类似 “首页 > 市场营销 > B2B 内容营销 > 策略” 这样的统一面包屑路径时,就会在你的网站与这些主题领域之间建立更强的语义关联。
面包屑的类型(以及该使用哪一种)
层级型面包屑是一种基于位置的面包屑,严格遵循网站的真实结构。实际展示效果如下:
首页 > 博客 > SEO > 技术 SEO
路径中的每一个层级都代表网站架构中的一个真实版块,清晰地向用户展示他们当前所处的位置,以及内容在整个网站中的层级关系。

这是最符合 Google 推荐的网站架构和结构化数据规范的一种面包屑类型。对于内容密集型网站来说,层级型面包屑尤为有效,因为它们可以按照主题集群的方式自然地组织信息。
但需要注意的是——面包屑层级必须与你的 URL 结构以及实际的网站组织方式保持一致。如果你的面包屑显示为“首页 > 产品 > 电子产品 > 手机”,而 URL 却是 “/random-product-123”,那么就会让搜索引擎爬虫对你真实的网站结构产生困惑。
示例:一家销售跑鞋的电商网站,理想的面包屑应为:“首页 > 运动鞋类 > 跑鞋 > 男士 > 越野跑”
对应的 URL 结构应是:example.com/athletic-footwear/running-shoes/mens/trail-running/
但如果某个产品页面的 URL 是:example.com/products/trail-shoe-xt-5000,那它就完全无法与上述面包屑结构匹配,从而削弱结构清晰度和 SEO 效果。
基于属性的面包屑用于展示用户通过筛选条件所形成的浏览路径,例如:“首页 > 鞋类 > 女士 > 跑步 > 红色 > 8 码”。路径中的每一个元素都代表用户做出的一次筛选选择。
这种面包屑类型非常擅长反映用户意图和购物行为,尤其适合产品目录类网站和各类分类/目录型站点。
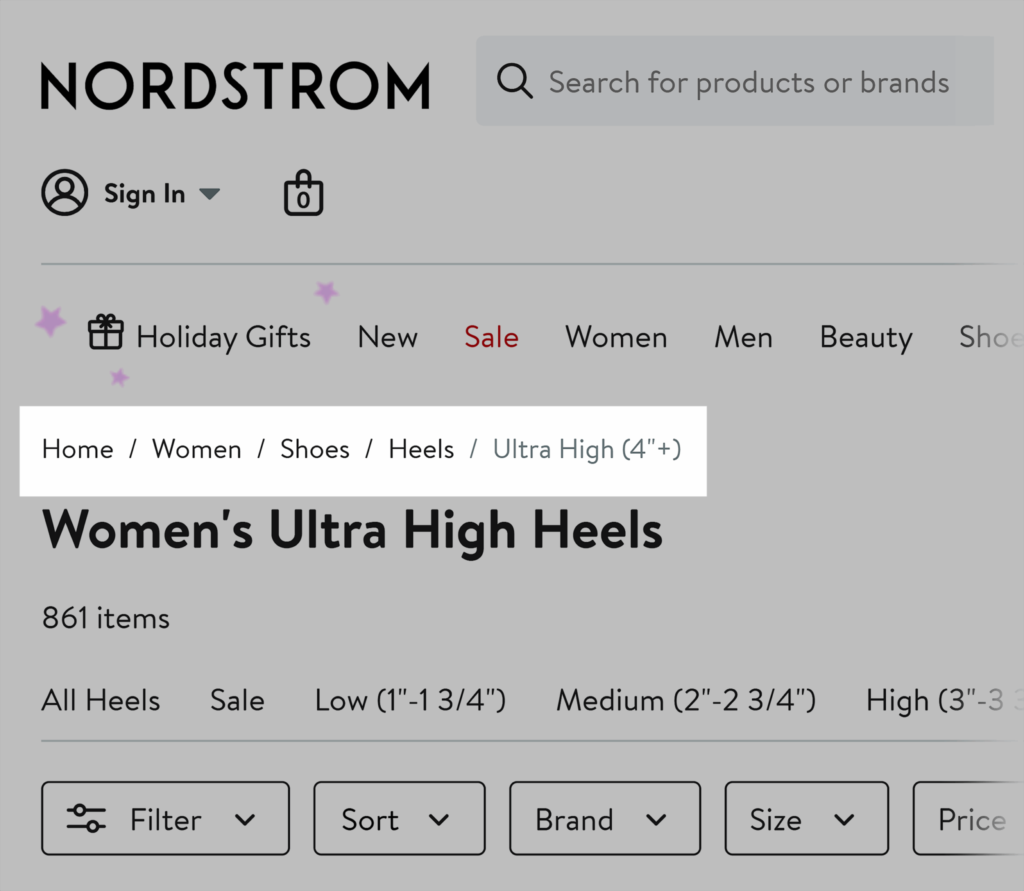
示例:Nordstrom 在其服装搜索中广泛使用基于属性的面包屑。例如在搜索超高跟鞋时,可能会显示:“首页 > 女士 > 鞋类 > 高跟鞋 > 超高(4 英寸以上)
前向型面包屑(逐步引导路径)
前向型面包屑(也称为预览型面包屑)用于展示用户在预设流程中的进度,例如:“步骤 1:账户设置 > 步骤 2:支付信息 > 步骤 3:确认”。
这种面包屑常见于结账流程和多步骤表单中。在 Amazon、Shopify 等电商网站上尤为常见,帮助用户清楚地了解自己当前所处的购买阶段,以及在完成订单前还剩多少步骤。
需要注意的是,这类面包屑并非传统意义上的 SEO 面包屑,因为它们并不直接体现网站的层级结构,而是更侧重于用户体验和转化率优化。不过,通过降低用户中途放弃的概率,它们仍然可以改善用户行为信号,从而间接对 SEO 产生积极影响。
历史型面包屑(较少使用的路径)
历史型面包屑用于展示用户到达当前页面时所经过的真实浏览路径,它们记录的是用户行为,而不是网站的结构层级。
由于无法向搜索引擎提供一致、稳定的结构信号,历史型面包屑对 SEO 的价值最低,通常不建议作为主要的 SEO 导航方案。
面包屑如何提升抓取能力与网站结构
面包屑为搜索引擎爬虫创建了可循的导航路径,帮助它们理解网站架构,同时通过层级结构分配链接权重,避免页面成为孤立页面。
要知道,爬虫会不断判断哪些页面最重要。面包屑就像一张路线图,持续向搜索引擎传递清晰、一致的导航信号,从而强化网站的逻辑结构。
真正的核心价值在于链接权重的分配。传统的内部链接往往需要人工决定链接哪些页面,而面包屑通常可以通过模板或批量方式生成,实现自动化内部链接。
这对大型网站尤为关键。拥有成千上万商品的电商网站可以从中获得巨大收益,因为面包屑能确保每个产品页面都会稳定地向所属分类页面传递内部链接。父级分类页面权重增强后,又能反过来帮助子页面获得更好的排名,形成一个正向循环。
真实案例:某在线电子产品零售商拥有 15,000 个产品页面,在启用层级型面包屑后,每个产品页面都会自动链接到:
-
子分类页面(例如:“游戏笔记本”)
-
分类页面(例如:“笔记本电脑”)
-
部门页面(例如:“电脑”)
-
首页
这意味着,无需任何额外的人工内部链接工作,就有 15,000 条具有上下文意义的链接持续指向分类页面。
面包屑还有效解决了孤立页面问题。缺乏明确导航路径的页面往往难以被爬虫发现,而面包屑可以确保每一个页面都始终保留一条清晰、可追溯的路径回到首页。
如何为 SEO 实施面包屑
通过层级结构分配内部链接权重
面包屑会自动将每个页面连接到其在网站结构中的对应位置。如果你拥有成千上万的产品页面,这就意味着成千上万条有价值的内部链接,用来强化网站整体的组织结构。
由于面包屑会随着内容规模自动扩展,它们在效果和效率上都优于人工内部链接。每当你发布一个新页面,它都会立即获得正确的上下文关系和必要的内部连接,而且几乎不需要额外的工作量。
面包屑 Schema 结构化数据详解
面包屑 Schema 结构化数据通过使用 JSON-LD 格式定义每一层级的位置、名称和 URL,帮助搜索引擎理解你的网站导航层级结构。
BreadcrumbList 是承载所有面包屑项的核心容器,而其中的每一个面包屑元素都必须使用 ListItem 标记,Google 才能正确解析。
对于 Google 来说,每一个 ListItem 都需要包含以下三个核心属性:
-
item:该层级面包屑对应的 URL(对当前页面而言可选)
-
position:该面包屑在路径中的顺序(从 1 开始)
-
name:向用户展示的文本内容
{
"@context": "https://schema.org",
"@type": "BreadcrumbList",
"itemListElement": [{
"@type": "ListItem",
"position": 1,
"name": "Home",
"item": "https://example.com/"
}, {
"@type": "ListItem",
"position": 2,
"name": "SEO Tools",
"item": "https://example.com/seo-tools"
}]
}
最后一级面包屑代表当前页面,因此不需要包含 item 属性。同时,请务必确保你的 JSON-LD 与页面上可见的面包屑完全一致,否则可能会在 Google Search Console 中触发警告。
分步实施指南:
-
将 JSON-LD 添加到页面模板中将结构化数据放置在
<head>标签内,或紧接在<body>开始标签之后。 -
使用绝对 URL始终包含完整 URL 及协议,例如:
https://example.com/category,而不是/category。 -
与可见面包屑保持一致确保 JSON-LD 的层级、名称和顺序与用户在页面上看到的面包屑完全相同。任何不匹配都可能导致 Google Search Console 发出警告。
-
验证结构化数据在上线之前,使用 Google 的 富媒体结果测试(Rich Results Test) 检查是否存在错误。
-
在 Search Console 中持续监控前往 增强功能 → 面包屑,跟踪错误、警告和有效项目。需要长期监控,因为网站结构或模板的变更都可能影响面包屑的验证状态。
WordPress 实现方式
对于 WordPress 网站,有多款插件可以简化面包屑的实施流程:
Yoast SEO在 设置 > 高级 > 面包屑 中启用面包屑后,Yoast 会自动生成面包屑 Schema 结构化数据。该插件负责 JSON-LD 的生成,并确保结构化数据与页面上可见的面包屑保持同步。
Rank MathRank Math 提供了类似的功能,同时还支持更多自定义选项,例如分隔符样式、锚文本设置以及分类法(taxonomy)的选择。
自定义 CMS 实现方式
对于自定义构建的网站,应创建一个面包屑函数,用于:
-
生成页面上可见的面包屑导航
-
同时构建对应的 JSON-LD 数据数组
-
确保两者在每次页面加载时始终保持同步
具备更高开发能力的开发者可以使用 PHP 脚本语言 来完成这些自定义实现。以下是一个使用 PHP 逻辑的示例说明了这种做法:
function generate_breadcrumbs() {
$breadcrumbs = [];
$breadcrumbs[] = ['name' => 'Home', 'url' => home_url()];
// Add category hierarchy
if (is_single()) {
$categories = get_the_category();
foreach ($categories as $category) {
$breadcrumbs[] = [
'name' => $category->name,
'url' => get_category_link($category->term_id)
];
}
}
// Convert to JSON-LD
return build_breadcrumb_schema($breadcrumbs);
}
对于具备 PHP 开发经验的开发者来说,构建自定义面包屑函数相比基于插件的方案具有显著优势。PHP 让你能够完全掌控面包屑的逻辑,从而根据具体的网站架构和内容类型进行高度定制。
这种方式还能避免插件带来的额外负担,减少潜在冲突,并有助于提升页面加载速度。此外,由于代码由你直接维护,当 CMS 发生任何变更时,面包屑也可以立即适配,无需等待第三方插件的更新。
需要避免的常见面包屑错误
面包屑相关的错误可能会悄无声息地削弱数月的 SEO 成果,其中影响最严重的问题往往出现在技术实现层面。下面我们将结合实际情况,看看这些问题具体体现在哪里,以及如何正确添加面包屑。
在不同页面层级中出现重复的面包屑路径
当同一产品可以通过多个分类结构访问时,就会产生相互冲突的面包屑路径。例如,同一个产品同时显示为:“首页 > 电子产品 > 笔记本电脑 > MacBook Pro”和“首页 > Apple > 笔记本电脑 > MacBook Pro”。
这种情况会削弱层级结构信号,并可能引发规范化(canonical)问题。虽然 Google 在索引时并不强制要求面包屑路径必须与 URL 完全一致,但不匹配的面包屑仍可能在 Search Console 中触发警告,同时降低爬虫对网站结构的理解清晰度。
修复原则:为每一条内容确立唯一的主层级路径。
解决方案:可基于以下因素实现规范化的面包屑路径:
-
在 CMS 中指定的主分类
-
URL 结构(优先使用 URL 中体现的分类)
-
用户入口来源(根据来源页面动态调整展示路径)
标签命名不一致
不一致的面包屑标签会同时让用户和搜索引擎感到困惑。举例来说,如果同一个分类在某些页面中使用 “服务”,而在其他页面中却显示为 “我们做什么”,就会破坏帮助爬虫理解网站层级结构的语义信号。
为避免这种情况,建议建立一套统一的主分类体系(Master Taxonomy),为网站每一个层级明确规定唯一且固定的分类名称,并确保所有面包屑严格遵循这一命名规范。
同时,应定期审查面包屑——建议至少每季度检查一次,以便及时发现命名偏差或不一致问题,从而为用户和搜索引擎持续提供清晰、可靠的层级信号。
缺失或格式错误的 Schema 结构化数据
常见的 Schema 结构化数据错误包括:
-
缺少 position(位置)值
-
使用了无效的 URL
-
使用相对 URL 而非绝对 URL
-
@type 声明错误
-
缺少必填属性
上述任何一种问题,都会导致 Google 无法正确解析你的网站层级结构。
为了确保 Schema 不存在错误,建议在上线前使用 Google 富媒体结果测试(Rich Results Test) 进行验证。你的 JSON-LD 应在每一个层级中正确包含 @type、itemListElement、position、name 和 item 等关键属性。
链接到非规范(Canonical)URL
当面包屑链接指向包含大量参数的 URL(如跟踪参数、会话 ID、筛选参数),或仍然使用 HTTP 而非 HTTPS 的页面时,相当于向搜索引擎传递了错误的首选版本信号。这会导致权重分散,并造成抓取效率下降。
因此,面包屑中的链接必须始终指向每个层级对应的规范(Canonical)URL。在生成面包屑标记之前,应实现 URL 清理逻辑,自动移除不必要的参数。
错误示例(不要这样做):首页 > Category?ref=nav&sort=popular > Product
正确做法:首页 > Category > Product
JavaScript 渲染的面包屑
如果面包屑仅通过客户端 JavaScript 渲染,那么对许多搜索引擎爬虫来说,它们可能是不可见的。一个简单的测试方法是:禁用 JavaScript,如果面包屑随之消失,就说明你的实现需要改为服务器端渲染。
虽然 Google 可以渲染 JavaScript,但相比直接解析服务器端输出的 HTML,速度更慢、稳定性也更低。对于像面包屑这样的重要导航元素,强烈建议采用服务器端渲染或预渲染,以获得最佳的可靠性和 SEO 效果。
你还可以使用 Google Search Console 的“URL 检查”工具,验证 Google 是否能够成功看到并渲染你的面包屑。
面包屑与移动优先索引(Mobile-First Indexing)
移动优先索引使得在响应式设计中正确实施面包屑变得尤为关键。由于 Google 现在仅使用移动端版本进行索引,如果桌面端与移动端的面包屑标记不一致,就可能导致结构化数据验证错误。
在小屏设备上,面包屑也成为重要的导航指引工具。一些更智能的移动端实现方式包括:
横向滚动显示:允许用户左右滑动查看完整的面包屑路径。例如,在层级较深的产品页面中:“首页 > 电子产品 > 音频 > 耳机 > 无线 > 头戴式 > Sony WH-1000XM5”移动端用户可以通过向左滑动来查看前面的层级,而不是只看到被截断的“首页 > … > Sony WH-1000XM5”。
仔细想一想:这种方式既能保留完整的导航上下文,又不会让移动端布局显得拥挤。如果配合一组左右滑动前后的对比截图,将能非常直观地展示这一效果。
可折叠的父级分类:只显示最近一级父分类,并通过下拉方式展开完整层级。例如,在“无线耳机”的产品页面上,可以仅显示 “电子产品” 作为可见父级,同时配合一个小箭头图标,点击后展开完整路径:首页 > 电子产品 > 音频 > 耳机 > 无线耳机。这样既保持了面包屑的简洁,又在用户需要时提供了完整的导航上下文。
但关键点在这里:无论桌面端还是移动端,Schema.org 的 BreadcrumbList 结构化数据必须保持完全一致。即使移动端界面中对面包屑进行了截断,JSON-LD 也应始终包含完整的层级路径。
如果你的移动端优化策略是将面包屑隐藏在汉堡菜单中,那么你可能正在破坏帮助搜索引擎理解网站结构的语义信号。请确保面包屑在移动端保持可见,或者至少保证结构化数据仍然存在于页面源代码中。
面包屑在 AI 搜索与现代 SERP 中的作用
面包屑导航可以帮助AI 驱动的搜索系统更好地理解内容之间的关系以及网站的层级结构。随着生成式 AI 引擎对网页内容的处理不断加深,结构化的面包屑数据正在成为一种重要的上下文信号。
从 大语言模型(LLM) 的信息理解方式来看,上下文至关重要。当 AI 能够追溯某个页面的面包屑路径时,例如:首页 > 技术 SEO > JavaScript 优化,一篇关于 “JavaScript SEO” 的页面就会被赋予更强的专业深度和主题聚焦信号,从而提升内容在语义层面的权重。
基于实体的排名演进正在改变一切。Google 的算法正越来越多地关注主题之间的语义关联。你的面包屑结构,可能正在成为一张“路线图”,帮助 AI 系统理解内容集群如何与更广泛的行业概念建立联系。
现代搜索体验——包括语音搜索、AI 对话界面以及上下文推荐——都高度依赖结构化数据。当 Google 为富媒体结果或 AI 驱动的功能评估内容时,拥有清晰层级结构和一致主题信号的网站更容易被理解和解析。
需要说明的是,截至目前,Google 尚未确认 AI 模型会直接解析面包屑作为排名因素。其价值主要体现在结构和语义层面的上下文强化,而不一定是直接的排名信号。
示例:一个显示为“首页 > 数字营销 > SEO > 技术 SEO > 核心网页指标(Core Web Vitals)”的页面,相比一篇孤立存在的博客文章,更能向搜索引擎和 AI 系统传达全面、系统的内容覆盖深度。

测试与监控面包屑的性能表现
Google Search Console 监控
前往 Search Console > 增强功能 > 面包屑,检查以下内容:
-
有效项目:已正确实施面包屑 Schema 的页面
-
警告:非关键问题,但仍建议尽快修复
-
错误:会阻止 Google 解析结构化数据的严重问题
建议开启错误邮件提醒,以便在出现新问题时能够第一时间发现并处理。
结构化数据测试工具
建议定期使用以下工具进行检测:
-
Google 富媒体结果测试(Rich Results Test)最适合用于检测页面是否符合 Google 富媒体结果的展示资格。它可以验证你的面包屑 Schema 是否按照 Google 的要求正确实施,并显示页面是否有机会以增强型搜索结果形式呈现。
-
Schema Markup Validator更适合进行结构化数据语法层面的详细校验。该工具会检查你的 JSON-LD 是否符合 Schema.org 规范,发现错误或缺失属性,并且适用于 Google 以外的其他搜索引擎。
-
Screaming Frog SEO Spider可对整个网站的面包屑 Schema 进行审计,识别缺失或格式错误的标记、不一致的层级结构以及重复路径。非常适合进行批量验证和全站级监控,可作为 Rich Results Test 和 Schema Markup Validator 的有力补充。
抓取效率指标
可在 Google Search Console 中监控以下指标,以衡量面包屑带来的影响:
-
抓取预算分配:关键页面是否被更频繁地抓取?
-
页面发现速度:新页面被发现的速度是否提升?
-
索引覆盖情况:此前的孤立页面是否已被成功索引?
通过对比实施面包屑前后的这些数据指标,可以更直观地量化面包屑对抓取效率和整体 SEO 表现所带来的实际效果。
关键要点与实施清单
Google 虽然在移动端搜索结果中移除了面包屑的可视展示,但其背后的结构化数据依然在幕后持续发挥作用。可以把它想象成管道系统——平时看不见,但一旦缺失,整个系统都会出问题。
当一些竞争对手因为看不到即时的 SERP 展示收益而放弃面包屑实施时,具有前瞻性的团队反而会加倍投入技术基础建设。随着 Google 向基于实体的搜索和 AI 搜索体验不断演进,拥有清晰层级结构的网站将获得更多回报,而这正是规范实施面包屑所能提供的核心价值。
面包屑实施检查清单
技术设置:
-
审核当前面包屑结构,确保符合 Schema.org 的 BreadcrumbList 规范
-
使用 Google 富媒体结果测试(Rich Results Test) 验证结构化数据
-
确保面包屑通过服务器端渲染,而非仅客户端渲染
-
所有面包屑链接均使用绝对 URL
-
面包屑层级与 URL 结构保持一致
移动端优化:
-
测试面包屑在移动端与桌面端的响应式表现
-
验证两端使用完全一致的 JSON-LD 标记
-
确保面包屑在移动端可见或可访问
持续维护:
-
在 Search Console 中设置结构化数据错误监控
-
建立内容治理流程,保持面包屑的一致性
-
每季度进行一次标签命名一致性审计
-
监控抓取效率指标,评估实施效果
内容策略:
-
为每一条内容确立唯一的主层级路径
-
记录产品或内容的规范分类归属
-
建立包含标准化分类名称的主分类体系
-
针对新增内容类型,审查其面包屑路径
未来趋势:未来更有利于那些尽早建立清晰语义架构的网站。结构清晰的内容层级和面包屑,能够帮助 Google 理解页面与主题之间的关系,增强主题权威性与层级清晰度——而这两点在传统搜索以及 AI 驱动的搜索功能中都变得越来越重要。
准备好开始了吗?你可以参考 Google 官方的结构化数据文档,了解所有技术要求;或者进一步学习网站架构的最佳实践,确保从一开始就正确实施。