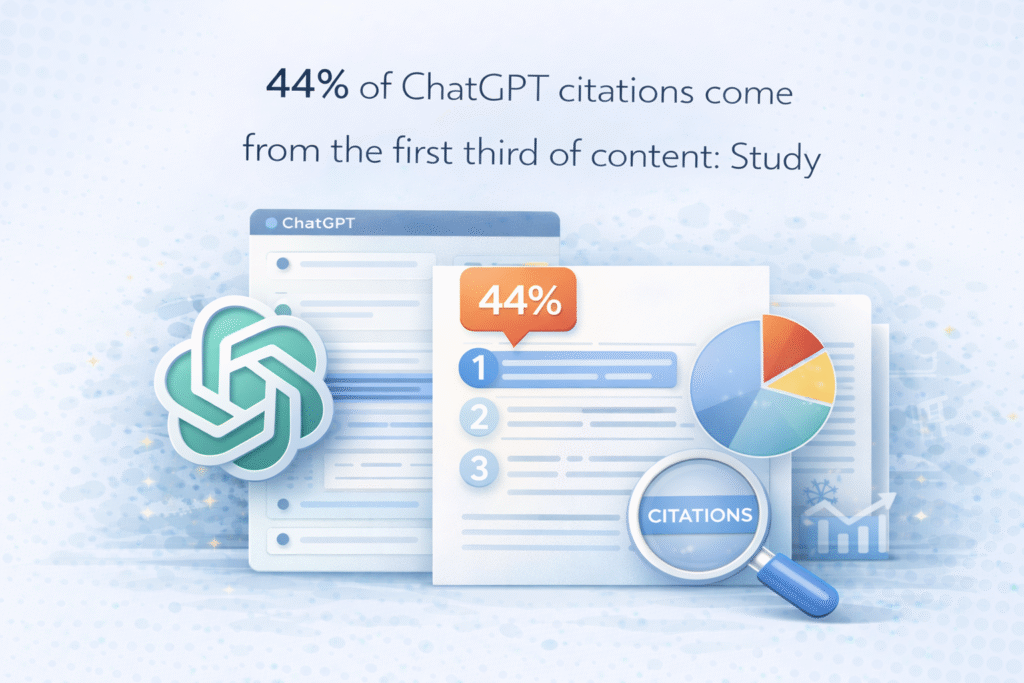
最新研究发现,ChatGPT 在选择引用时更倾向于内容的前半部分,偏好直接的定义、平衡的语气以及高密度的实体信息。
根据增长顾问 Kevin Indig 对 120 万条 AI 回答和 18,012 条已验证引用的分析,ChatGPT 在选择引用时明显偏向内容的开头部分。
为什么这很重要传统搜索更看重内容的深度和延后呈现的价值。而 AI 更偏好即时分类——在开头就提供清晰的实体和直接的答案。如果你的核心内容没有在前面突出呈现,它出现在 AI 回答中的可能性就会降低。
数据说明Indig 的团队发现了一种一致的“滑雪坡道”式引用模式,并且在随机验证批次中都得到了相同结果。他表示这些结果在统计学上无可争议:
- 44.2% 的引用来自内容的前 30%。
- 31.1% 来自中间部分(30%–70%)。
- 24.7% 来自最后三分之一,并且在接近页脚处出现明显下降。
在段落层面,AI 的阅读更为深入:
- 53% 的引用来自段落的中间部分。
- 24.5% 来自首句。
- 22.5% 来自末句。
核心要点在文章层面,应将关键信息前置;在段落内部,则应优先保证表达清晰和信息密度,而不是刻意强调“强开头”的首句。
原因分析大型语言模型的训练数据多来自新闻报道和学术写作,这些内容通常采用“结论先行”的结构。模型似乎会对前期的框架信息赋予更高权重,然后在此基础上理解后续内容。
- 现代模型虽然能够处理大量的 token(文本片段),但它们仍然优先追求效率,并快速建立语境。
哪些内容更容易被引用 Indig 总结了高被引内容的五个特征:
1. 明确定义的语言被引用的段落使用清晰定义(如 “X 是……”“X 指的是……”)的概率几乎是其他内容的两倍。直接的“主语-动词-宾语”句式优于模糊的表达方式。
2. 对话式问答结构被引用的内容出现问号的概率是其他内容的 2 倍。与问题相关的引用中,有 78.4% 来自标题。AI 常将 H2 标题视为“提问”,并把紧随其后的段落视为“答案”。
3. 实体信息丰富普通英文文本中专有名词占比通常为 5%–8%,而高被引文本的平均占比达到 20.6%。具体的品牌、工具和人物名称有助于锚定答案、减少歧义。
4. 情感倾向平衡被引用文本的主观性评分集中在 0.47 左右——既不过于枯燥客观,也不过于情绪化。AI 更偏好类似分析师评论的语气:事实加解读。
5. 商业级清晰度表现优异的内容平均 Flesch-Kincaid 阅读等级为 16,而表现较差的内容为 19.1。较短的句子和清晰的结构优于密集的学术化表达。
关于数据Indig 分析了 300 万条 ChatGPT 回答和 3,000 万条引用,从中筛选出 18,012 条已验证引用,以研究 AI 从哪里以及为何提取内容。其团队使用 sentence-transformer 嵌入模型将回答与具体来源句子匹配,并测量其页面位置及语言特征,例如定义表达、实体密度和情感倾向。
核心结论叙事型的“终极指南”写作在 AI 检索中可能表现不佳;结构化、简报式内容更具优势。
Indig 认为,这带来了一种“清晰度税”。写作者必须在开头就呈现定义、关键实体和结论,而不是把它们留到文章结尾。